Overview
This guide shows you how to log spans to Galileo using the@log decorator in Python, or the log wrapper in TypeScript to log function calls using the async OpenAI SDK as LLM spans.
In this guide you will:
Before you start
To complete this how-to, you will need:- An OpenAI API key
- A Galileo project configured
- Your Galileo API key
Install dependencies
To use Galileo, you need to install some package dependencies, and configure environment variables.Install Required Dependencies
Install the required dependencies for your app. If you are using Python, create a virtual environment using your preferred method, then install dependencies inside that environment:
Create the basic app to call OpenAI
Add the following code to call OpenAI to ask a question
package.json file:package.json
Add simple logging with the Galileo log decorator or wrapper
Galileo has a@log decorator in Python, and a log wrapper in TypeScript that logs function calls as spans. If these decorated or wrapped calls are called whilst there is an active trace, they are added to that trace. If there is no active trace, a new one is created for this span.
In this guide, you will be adding the decorator or wrapper to log the function that calls OpenAI.
Decorate or wrap the function
Update the function definition to include the decorator or wrapper:This will log the function as an LLM span using the span type parameter. You can read more about these in our span types documentation.This also sets the name of the span to “OpenAI GPT-4o-mini”.
Run the app
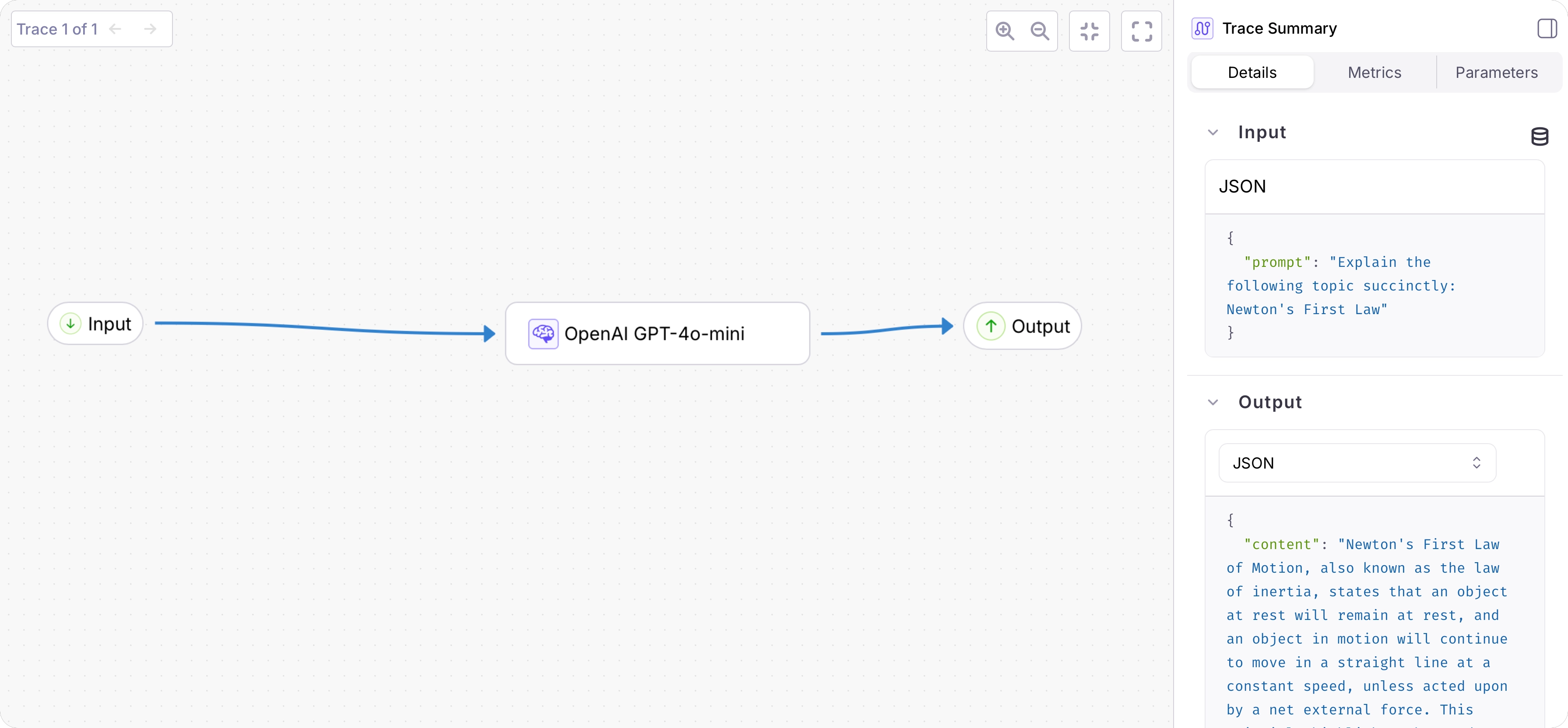
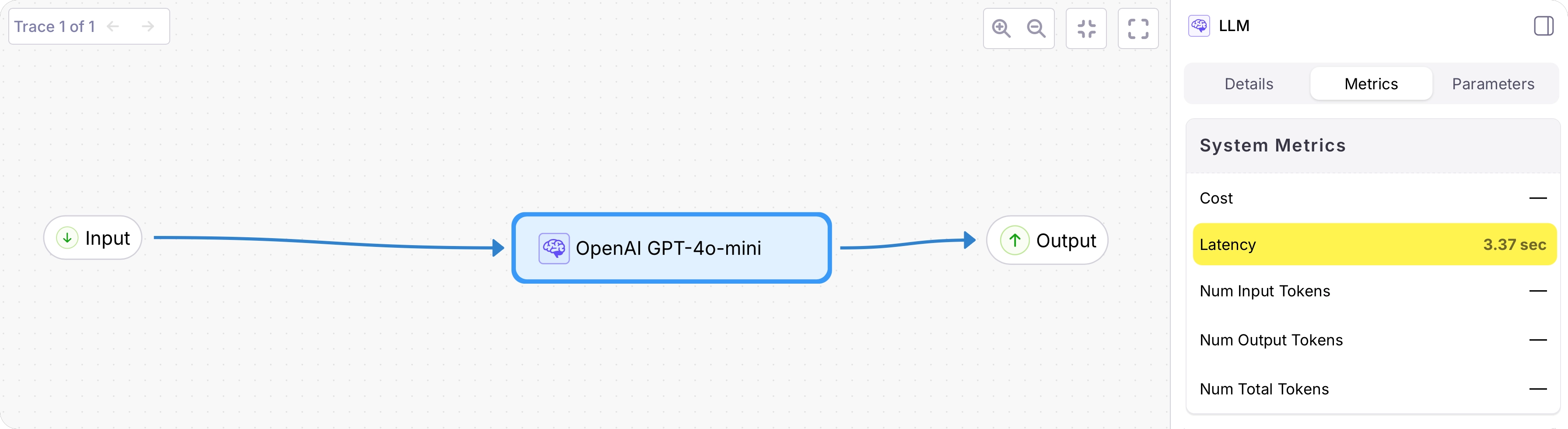
prompt, the output as the returned response. The duration will also be logged.View the logged trace
From the Galileo Console, open the Log stream for your project. You will see a trace with a single span containing the logged function call.Select the trace to see a detailed view: