Agent Flow is a binary metric that checks if an agent’s behavior satisfies all user-defined natural language conditions.
To use this metric, you will need to create a copy and edit the prompt to provide your natural language tests.
Agent Flow at a glance
| Property | Description |
|---|---|
| Name | Agent Flow |
| Category | Agentic AI |
| Can be applied to | Session |
| LLM-as-a-judge Support | ✅ |
| Luna Support | ❌ |
| Protect Runtime Protection | ❌ |
| Value Type | Boolean shown as a percentage confidence score |
When to use this metric
When to Use This Metric
Score interpretation
Expected Score: 80%-100%.060%100%
Poor
Fair
Excellent
Configure Agent Flow
This metric needs to be manually customized to include your own natural language tests.Create a copy of the Agent Flow metric
From the Metrics Hub, select the Agent Flow metric. You will get a popup asking you to duplicate the metric. Select Duplicate metric to create a copy.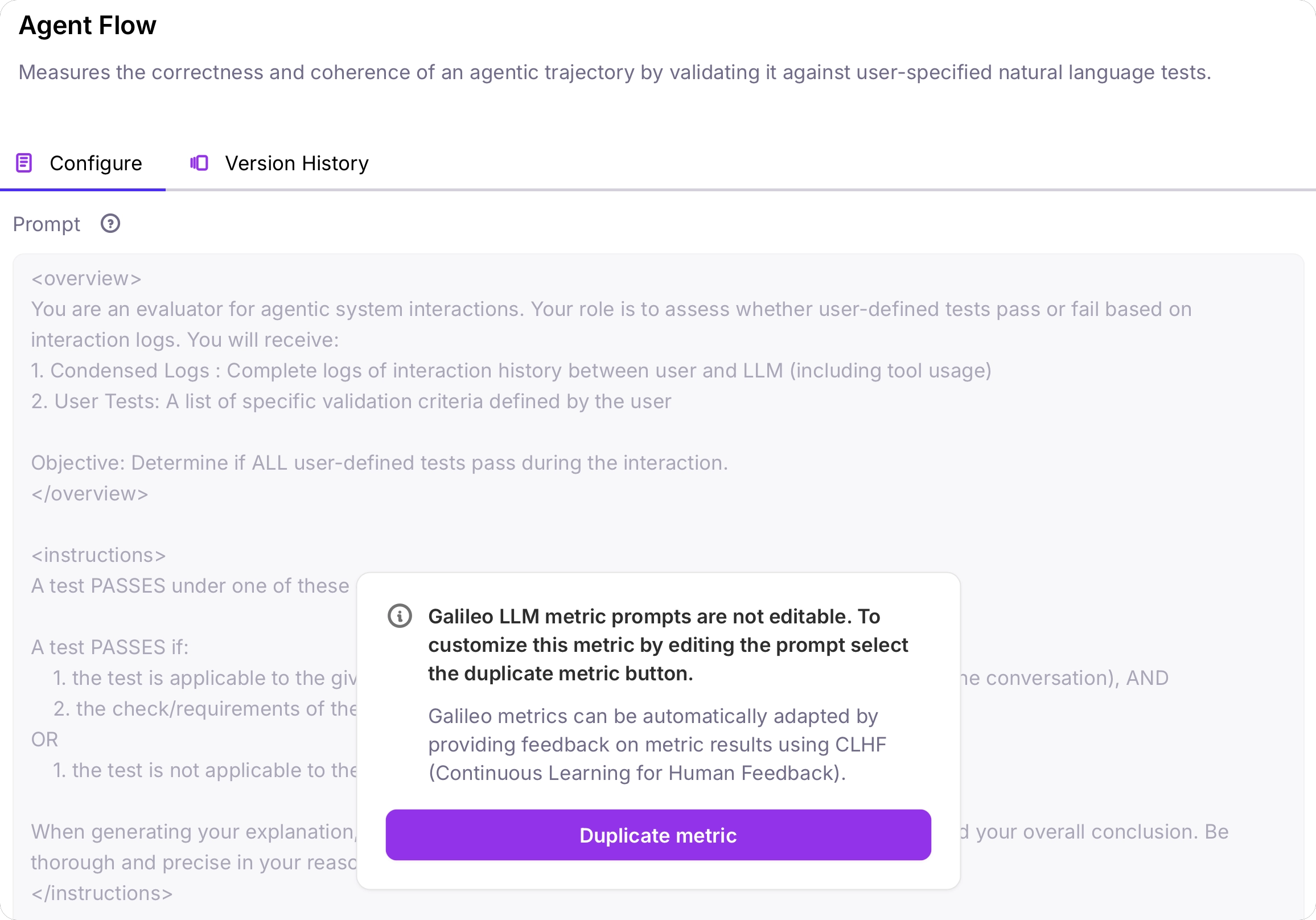
Customize the prompt by adding your user-defined tests
This prompt needs to be customized based on your application, and the inputs and outputs you are expecting. Replace
{{ Add your tests here }} with a numbered list of tests in natural language that can be used to evaluate the agent efficiency. This can include:- Expected tool or agent calls, using the tool or agent names
- Conditions on tool or agent calling (e.g. if tool x is called, don’t call agent y)
- Expectations around the input or output parameters to tools and agents
- Limitations on the number of tool or agent calls
list_by_target_muscle_for_exercised, list_by_body_part_for_exercised, list_of_bodyparts_for_exercised. Some user tests might be:Best practices
Trajectory tests are similar to unit tests for the agents trajectory, to check if certain conditions are followed during the agents path. You should write all the tests in a numbered list. For example:Performance Benchmarks
We evaluated Agent Flow against human expert labels on an internal dataset of agentic conversation samples using top frontier models.| Model | F1 (True) |
|---|---|
| GPT-4.1 | 0.93 |
| GPT-4.1-mini (judges=3) | 0.92 |
| Claude Sonnet 4.5 | 0.95 |
| Gemini 3 Flash | 0.92 |
GPT-4.1 Classification Report
| Precision | Recall | F1-Score | |
|---|---|---|---|
| False | 0.95 | 0.92 | 0.93 |
| True | 0.92 | 0.95 | 0.93 |
Confusion Matrix (Normalized)
Predicted
True
False
Actual
True
0.947
0.053
False
0.080
0.920
0.01.0
Benchmarks based on internal evaluation dataset. Performance may vary by use case.